
Technology pitstops – do you have one?
Technology pitstops are critical items I tell projects that they must consider. The way we produce, deliver and manage tech data today is vastly different to how we will provide data over the coming years. We only have to look at the changes in technological capability over the last few […]

Mandating IETP solutions of projects
Mandating IETP solutions on projects on the face may seem like a sensible strategic decision for many organisations. The reality is very different. There is an upside and downside to mandating a viewing solution to your projects. Some obvious and some not so obvious, so allow me to share some […]

Writing for formatted output – why we don’t do this with structured content
Writing for the formatted output is one of the key differences between traditional technical writing and structured writing methods. (video available on YouTube) In structured writing practise, we focus on the correct and schema conformant building blocks of our documents. We remove the emphasis from style, layout and look and […]

Sensible modular breakdown of our technical publication
Sensible modular breakdown question is an excellent topic of debate when we deconstruct our technical content, especially around S1000D, DITA, or other methods. This question came in from a subscriber looking to adopt S1000D for the first time. Embarking on S1000D adoption can be intimidating at the best of times, […]
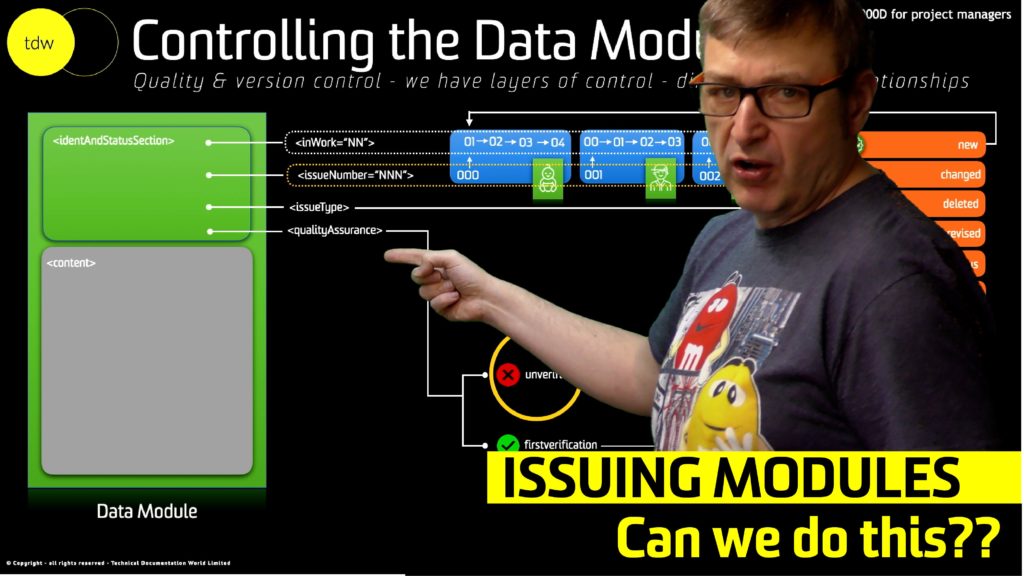
Issuing unverified S1000D modules
Issuing unverified S1000D modules was the question of the week this week. S1000D provides many controls over our data module’s state, ranging from version control numbers for controlling draft states and issues states of our modules. S1000D also includes quality assurance states for each module, enabling us to identify the […]
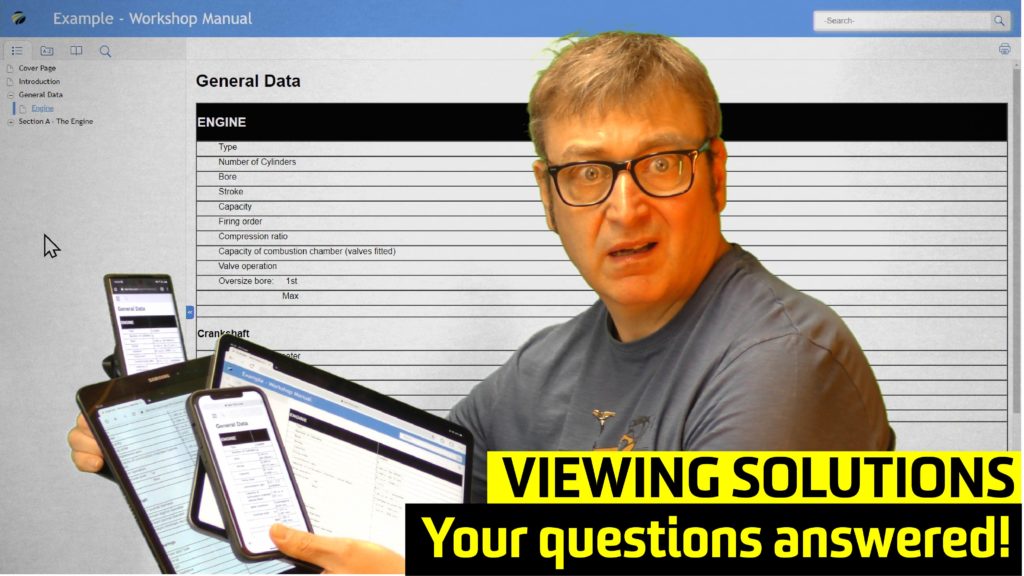
Selecting our technical documentation’s viewing solution – S1000D v non-S1000D
Selecting our technical documentation’s viewing solution is always a bit of a challenge, especially if we are not 100% sure of the existing alternative options. The starting question is, “are we using S1000D?”. As I have mentioned in many blogs and articles, S1000D is one way to produce technical documentation. […]

Data reuse in S1000D – the good, the bad and the reality
Data reuse in S1000D – the good, the bad and the reality! Often I am asked to explain what is meant by data reuse, specifically when it comes to S1000D. Confusion exists as this is a common buzzword thrown around when being ‘sold’ S1000D. We will often hear S1000D is […]

Confusion in S1000D – what we need to understand
Confusion in S1000D is not uncommon! I often have to spell out for clients the difference between eXtensible Markup Language (XML), or structure, S1000D (specification) and the role of supporting software (both XML and S1000D). XML delivers many incredible benefits to our content production and deployments. We can be flexible […]

The S1000D CSDB and the S-Series – Members question
The S1000D CSDB is a tool specifically designed to support the required and necessary, often complex, components of an S1000D project. A question came to us here at TDW, “Can you explain the CSDB and will it support the S-Series specifications?”. A reasonable question, but to answer this all together, […]

What does good looking like?
What does good look like is a question I tend to get from senior managers and decision-makers in organisations. Answering this question always takes a little bit of navigating as explaining to non-believers what S1000D is and why it does what it does is tricky to sell in an elevator […]